多 LLM ルーティング実践:AI API コストを60%削減する方法(Sonnet 4.6 + Haiku 4.5 分散処理)
多 LLM ルーティングは、タスクを難易度に応じて異なるモデルに振り分け、Haiku 4.5、Sonnet 4.6、Opus 4.7のコスト差を活用してAI APIの月額費用の増加を抑制します。月5Mトークンの実測では約60%のコスト削減が可能です。
なぜ月末のAI請求がどんどん膨らむのか?
AI APIのコストが膨らむ原因は、モデルの価格が上がったからではなく、すべてのタスクを同じ高性能モデルに任せているためです。
私たちは多くの中小企業のAI導入経路を見てきました。初月は文案作成、会議記録の要約、カスタマーサポートメッセージの整理で月額約NT$3,000。2ヶ月目からCRM、カスタマーサポートメール、SNSスケジューリング、社内ナレッジベースを追加し、トークンコストがNT$10,000に増加。3ヶ月目には自動化エージェント、バッチ書き換え、リストクリーニングを加え、月額はNT$30,000超に達します。
問題はAIが費用に見合わないのではなく、タスクのランク付けがされていないことにあります。
例えば、カスタマーサポートのメール一通にClaude Sonnet 4.6を使うべきか?場合によっては必要です。しかし、3,000件のリストを「B2B / B2C / 不明」に分類するのにSonnetを使う必要はほとんどありません。商品タイトルのフォーマット変換、会社名の抽出、JSONの欄補完などは高難度の推論を必要としません。
多くの企業がAI自動化で陥る罠は、APIを接続して効果を確認した後、すべての処理を最強モデルに任せてしまうことです。短期的には問題ありませんが、月末に小さなタスクも高単価で処理されていることに気づきます。
トークンコストはAIの「使用電力料金」と考えられます。トークンはモデルの入出力の文字単位で、input tokenは入力内容、output tokenはモデルの応答です。タスクが長く、回数が多く、高価なモデルを使うほど請求は高くなります。
もし企業がすでにClaude / Codex / Geminiツールセットを活用しているなら、次のステップはツールを増やすことではなく、モデルの使用権限を細分化し、どのタスクに安価なモデルを使い、どのタスクに高性能モデルを使うかを決めることです。
多 LLM ルーティングの核心価値はここにあります。AIの使用量を減らすのではなく、AIを適切な場所で使うことです。
多 LLM ルーティングとは?一言で説明
多 LLM ルーティングとは「タスクの難易度を判定し、適切なモデルに振り分ける」ことです。
簡単なタスクはHaiku 4.5、中程度のタスクはSonnet 4.6、複雑なタスクはOpus 4.7に送ります。これは企業内の仕事の割り振りに例えられます。資料整理はアシスタントに、標準分析はシニアスタッフに、重要な決定はコンサルタントに任せるイメージです。
これは技術的に美しく見せるためではなく、すべてのトークンコストに合理的なリターンをもたらすためです。
Anthropicの公式価格とモデルドキュメントによると、Claudeシリーズモデルは価格、速度、能力に違いがあります。詳細はAnthropic pricingおよびClaude models docsをご参照ください。外部リンクのrel="noopener"はフロントエンドテンプレートで統一処理しています。
コスト削減の計算式は簡単です:
節約率 % = 1 - (各モデルの費用合計) / (全てSonnet使用時の費用)例えば、月5MトークンをすべてSonnetで処理すると約NT$15,000かかります。これを70%Haiku、25%Sonnet、5%Opusに振り分けると、約NT$5,400~6,000に削減できます。約NT$9,000~9,600の節約、つまり約60%のコスト削減です。
この60%は魔法ではなく、70%以上のタスクが実際にはSonnetを必要としないことに由来します。
私たちはリスト分類、文案フォーマット変換、欄抽出、FAQ要約、カスタマーサポートメールの草稿作成などを実測しました。結果は明確で、タスクが固定フォーマット、低リスク、検証可能な回答であればHaiku 4.5で十分です。Sonnet 4.6が必要なのは、語調判断や複数情報の統合、対外公開可能なコンテンツ生成などのタスクです。
タスク難易度を3層に分類:Haiku / Sonnet / Opusの選び方
モデル振り分けで最も避けたいのは感覚的判断です。正しい方法はタスクを3層に分け、それぞれの層をワークフローに組み込むことです。
重要なのは「どのモデルが最も賢いか」ではなく「どのモデルがちょうど良いか」です。中小企業にとっては、十分な性能が最強より重要です。月に数万回の自動化呼び出しがある場合、単価の差が大きく影響します。
| 分類 | 例 | モデル | 月間トークン推定 | 月間コスト推定 |
|---|---|---|---|---|
| Tier 1(単純) | 分類、欄抽出、フォーマット変換、簡単な翻訳、タグ判定 | Haiku 4.5 | 3.5M tokens | 約NT$900-1,200 |
| Tier 2(標準) | 要約、返信、コードパッチ、SNS文案、営業メール草稿 | Sonnet 4.6 | 1.25M tokens | 約NT$3,600-4,000 |
| Tier 3(戦略 / 長文コンテキスト) | アーキテクチャ決定、クロスファイルリファクタリング、複雑なレビュー、戦略判断 | Opus 4.7 | 0.25M tokens | 約NT$900-1,200 |
上記のトークン数と費用は月5Mトークンの想定です。実際の請求は入力・出力比率、為替、キャッシュヒット率、モデルの公式価格変動により異なるため、導入前に自社ログで再計算が必要です。
Tier 1(単純タスク)→ Haiku 4.5
Tier 1の判定基準は明確です。回答フォーマットが固定、誤りが検出しやすく、深い推論を必要としないタスクです。
例:
- インバウンドリードを「高意図 / 中意図 / 低意図」に分類
- メールから氏名、会社名、役職、ニーズを抽出
- 200字の投稿を120字の短縮版に変換
- 英文製品概要を繁体字中国語に翻訳
- カスタマーサポートの問い合わせを会計、技術、物流、返金に分類
これらはHaiku 4.5に適しており、速度とコストを重視します。プロンプトで分類ルールを明確にし、JSONスキーマで出力し、失敗時はunknownを返す設計で品質管理が可能です。
私たちは1,000件のフォームリードをSonnetで分類していたものをHaikuに切り替え、分類精度は許容範囲を維持しつつコストを大幅に削減しました。人手で確認すべきはunknownや低信頼度のサンプルのみです。
Tier 2(標準推論)→ Sonnet 4.6
Tier 2は多くのAIワークフローの主力層です。タスクは文脈理解、情報取捨選択、語調コントロールを必要としますが、戦略的決定ではありません。
例:
- 30分会議の逐語録を行動項目に整理
- 顧客のクレームメールにブランド語調を保って返信
- 記事のアウトラインに基づくLinkedIn投稿作成
- エンジニア向け小規模コードパッチ作成
- 営業通話記録をCRMノートに変換
この層はSonnet 4.6が品質、速度、コストのバランスが良いため推奨されます。特に対外コンテンツやカスタマーサポート返信、営業メールは語調のずれがブランドコストに直結するため、単純なトークン単価だけで判断できません。
低コストAI導入ロードマップを計画中の企業では、Tier 2が最初に正式稼働するプロセスになることが多く、明確な人件費削減とROI算出が可能です。
Tier 3(戦略 / コードレビュー最終審査)→ Opus 4.7
Tier 3は少数ながら高リスクのタスクです。失敗時のコストはAPI費用の節約額を大きく上回ることがあります。
例:
- AI自動化アーキテクチャのサービス分割判断
- クロスファイルリファクタリング前のリスク分析
- コードレビューの最終審査とセキュリティチェック
- コンテンツ戦略、ポジショニング、コンバージョンファネル設計
- 長いコンテキストウィンドウ内での複数文書推論
この層はOpus 4.7や社内で最上位と認められたモデルに割り当てます。使用量は少なくて構いませんが、最も価値のある場所に配置することが重要です。
健全なコスト構造とは「大規模モデルを完全に使わないこと」ではなく、「大規模モデルは大規模モデルにふさわしいタスクだけを担当する」ことです。
ルーティング構成3種:ルール、LLM-as-Router、ハイブリッド
多 LLM ルーティングは単純にも複雑にもできます。中小企業は最初から完全なモデルガバナンスプラットフォームを構築する必要はなく、可観測性、ロールバック可能性、説明可能性のある構成から始めることを推奨します。
A:ルールベースルーティング(中小企業の初手に推奨)
ルールベースルーティングはif-else、タスクタイプ、トークン長、リスクレベルでモデルを決定します。
例:
if task_type in ["分類", "欄抽出", "フォーマット変換"]:
model = "Haiku 4.5"
elif token_count > 8000 or risk_level == "high":
model = "Sonnet 4.6"
elif task_type in ["アーキテクチャ決定", "複雑なレビュー"]:
model = "Opus 4.7"
else:
model = "Sonnet 4.6"この方法は最も安定かつ低コストで、デバッグも容易です。ログを見れば、なぜあるタスクがHaikuに割り当てられたか(例:task_type=分類)、なぜSonnetに昇格したか(例:入力が8,000トークン超)を即座に把握できます。
私たちは80%のシナリオでルールベースルーティングを推奨します。特にコンテンツ生成、カスタマーサポート振り分け、CRMデータクリーニング、SNS文案再利用など、タスクタイプが比較的固定されている場合は、毎回別のLLMに判断させる必要はありません。
B:LLM-as-Router(動的入力に適応)
LLM-as-Routerは安価なモデルを分類器として使い、タスクをどのモデルに送るか判定します。
例としてHaiku 4.5でユーザー入力を読み取り、以下のように出力します:
{
"tier": "tier_2",
"model": "Sonnet 4.6",
"reason": "複数のクレーム内容を統合し対外返信を生成する必要があるため",
"confidence": 0.86
}この構成は入力が不規則な場面、例えばカスタマーサポートメールボックス、オープンフォーム、社内Slackコマンド、エージェントのタスク割り当てに適しています。柔軟性は高いですが、モデル呼び出しが1回増えるため、すべてのタスクに無条件で適用するのは避けるべきです。
LLM-as-Routerでよくある失敗は、ルータープロンプトが抽象的すぎることです。「このタスクは難しいか?」ではなく、「多段推論が必要か」「対外送信か」「金額・法務・情報セキュリティに関わるか」「6,000トークン超か」など明確な評価基準を与えることが重要です。
C:ハイブリッド構成(本番環境に推奨)
本番環境ではハイブリッド構成を推奨します。ルールベースを主軸にし、LLMをフォールバックとして使います。
具体的には、70~80%のタスクは明確なルールで処理し、ルールで判断できない、信頼度が低い、入力が異常な場合のみHaiku 4.5をルーターとして呼び出します。さらにルーターが不確定ならSonnet 4.6に昇格させます。
実用的なフロー例:
| ステージ | 判定方法 | 結果 |
|---|---|---|
| 第1層 | task_type、token_count、risk_level | Haiku / Sonnet / Opusに直接振り分け |
| 第2層 | ルールで判定不可時、Haikuをルーターとして使用 | tier、confidence、reasonを返す |
| 第3層 | confidence < 0.75 または高リスク | Sonnetに昇格 |
| 第4層 | Sonnetが不確定または高影響決定 | Opusまたは人手レビューに昇格 |
ハイブリッド構成の利点はコスト管理が可能で、硬直したルールに縛られず柔軟に対応できることです。AIチームのワークフローに組み込みやすく、各タスクに初期モデルを割り当て、必要に応じて昇格させる設計が可能です。
実際にどれだけ節約できるか?月5Mトークンの全体試算
私たちは月5Mトークンを想定した中小企業の典型的なシナリオを試算しました。この企業はカスタマーサポート要約、リスト分類、SNS文案、社内SOP問答、簡単なコードパッチを毎日数百~数千回API呼び出ししています。
BeforeはすべてSonnet 4.6で処理:
| 項目 | モデル | トークン割合 | 月間トークン数 | 月間コスト推定 |
|---|---|---|---|---|
| 全タスク | Sonnet 4.6 | 100% | 5M | 約NT$15,000 |
| 合計 | - | 100% | 5M | 約NT$15,000 |
Afterはルールベースで70/25/5に分散:
| タスクレベル | モデル | トークン割合 | 月間トークン数 | 月間コスト推定 |
|---|---|---|---|---|
| Tier 1 単純タスク | Haiku 4.5 | 70% | 3.5M | 約NT$900-1,200 |
| Tier 2 標準タスク | Sonnet 4.6 | 25% | 1.25M | 約NT$3,600-4,000 |
| Tier 3 戦略タスク | Opus 4.7 | 5% | 0.25M | 約NT$900-1,200 |
| 合計 | - | 100% | 5M | 約NT$5,400-6,000 |
Before / Afterの比較:
| 指標 | Before:全Sonnet | After:多LLMルーティング |
|---|---|---|
| 月間トークン数 | 5M | 5M |
| モデル構成 | Sonnet 100% | Haiku 70% / Sonnet 25% / Opus 5% |
| 月間コスト | 約NT$15,000 | 約NT$5,400-6,000 |
| 月間節約額 | - | 約NT$9,000-9,600 |
| コスト削減率 | - | 約60% |
経営視点で見ると:
| 項目 | 数値 |
|---|---|
| 月間節約額 | NT$9,000-9,600 |
| 年間節約額 | NT$108,000-115,200 |
| 換算例 | コンテンツアシスタントの工数、広告テスト予算、CRM清掃プロジェクト |
| 導入コスト回収期間 | 構築費用NT$30,000なら約3~4ヶ月で回収可能 |
これがAIコストをROIとセットで見るべき理由です。API費用だけを見ると数千円の節約に見えますが、AIチームROIを分解すると、毎月の固定APIコスト削減が粗利改善に直結します。
もう一つのポイントは、ここにプロンプトキャッシュは含まれていません。ワークフローで同じシステムプロンプト、ブランド語調ルール、ナレッジベース要約を繰り返し使う場合、プロンプトキャッシュでさらにコスト削減が可能です。

ルーティング実装でよくある3つの失敗
多 LLM ルーティングはHaikuをすべてに使うことではありません。難しいのは分散ではなく、いつ節約すべきでないかを知ることです。
1つ目の失敗:Haikuの過剰使用。
Haiku 4.5は分類、欄抽出、フォーマット整理に適していますが、複雑な推論には向きません。小さな節約で大きな損失を招くのは、対外カスタマーサポート返信、契約条項要約、技術的意思決定、クロスドキュメント分析、長いコンテキストウィンドウを必要とするタスクです。
解決策は品質指標をルールに組み込むことです。高リスク、不可逆、対外送信、金額判断、法務・情報セキュリティ関連タスクは直接Haikuに回さず、たとえ最初にHaikuを使ってもSonnetで再検証します。
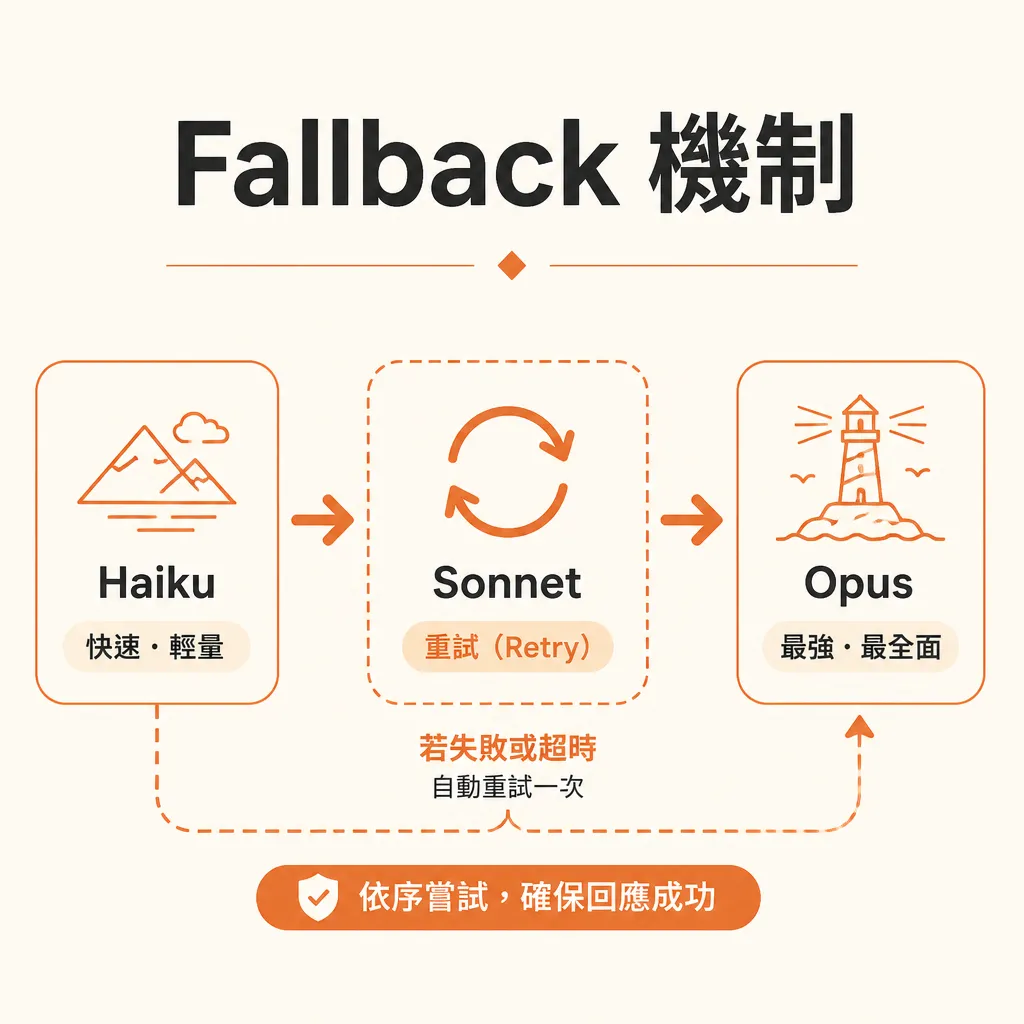
2つ目の失敗:フォールバック未実装。
多くのチームは「分類タスクはHaiku」とだけ書き、Haikuが失敗した場合の対応を書いていません。結果、JSON形式エラー、信頼度低下、入力過長、空白回答で処理が停止します。
基本的なフォールバックルールは以下の通りです:
Haikuが形式エラー → 1回リトライ
リトライ後も失敗 → Sonnetに昇格
Sonnetも不確定 → 人手レビューにマーク
高リスクタスク → 自動送信せず草稿のみ生成3つ目の失敗:プロンプトキャッシュを無視。
モデル分散に時間をかけても、毎回5,000トークンのブランドルール、製品知識、カスタマーサポートSOPを送り直すチームがあります。この場合、プロンプトキャッシュによる節約がモデル分散以上に大きくなります。
特にTTL(time to live)が5分のキャッシュが大量呼び出しに有効です。例えば200件の商品説明のバッチ書き換え、同じナレッジベースの500件質問回答、同じブランドルールで100件のSNS文案生成など、キャッシュヒット率が請求に直結します。
キャッシュ、ルーティング、フォールバックは一体設計し、孤立させないことを推奨します。
品質管理はどうする?毎月のサンプリングレビュー計算式
コスト削減は第一歩であり、品質管理ができなければ節約分を誤り修正に使うことになります。
私たちは毎月50件のHaikuルーティング結果を抽出し人工レビューを推奨します。抽出はタスクタイプ別に分け、分類20件、欄抽出10件、フォーマット変換10件、簡単翻訳10件などをカバーします。
品質計算式:
誤答率 = 誤りサンプル数 / 抽出サンプル数判定基準:
| 誤答率 | 対応 |
|---|---|
| < 5% | Haikuルーティング継続 |
| 5%-10% | プロンプト調整、例示追加、翌月観察 |
| > 10% | Sonnetに昇格、タスク境界再定義 |
なぜ5%か?多くの中小企業のAI自動化は研究ではなく運用プロセスです。5%の誤答率は100回に5回の修正が必要で、低リスクタスクでは許容範囲ですが、対外メッセージ、見積もり、契約、医療、法務、情報セキュリティでは許されません。
品質管理は「正誤」だけでなく、以下3指標も見るべきです:
| 指標 | 定義 | リスクシグナル |
|---|---|---|
| フォーマット成功率 | JSON / Markdown / フィールドスキーマ遵守率 | 98%未満はプロンプト調整必要 |
| 昇格率 | HaikuからSonnetへのフォールバック率 | 急増はタスク入力変化の兆候 |
| 人工修正時間 | 1件あたりの修正工数 | 節約時間を超えたらルーティング非効率 |
これらを毎月の運用レビューに組み込むことで、API請求だけを見るより有効な管理が可能です。どのタスクが安価モデルに適し、どれが見かけ上安価なだけかを把握できます。
もしAI導入ROIを算出中なら、「APIコスト節減」「人工修正時間」「誤答による再作業」を同一表にまとめ、純利益を明確にしましょう。
よくある質問(FAQ)— 4問以上(FAQPage schema対応)
Q1 Haiku 4.5はSonnetを完全に代替できますか?
完全な代替はできません。Haiku 4.5は低リスク、固定フォーマット、検証可能な回答が求められる分類、欄抽出、短文書き換え、簡単翻訳に適しています。
Sonnet 4.6は標準推論、対外コンテンツ、カスタマーサポート返信、コードパッチなどに適しています。正しい運用はHaikuで60~70%の単純タスクを処理し、Sonnetは必要なタスクに限定することです。
Q2 ルールベースルーティングはどのようにモデルを選択しますか?
4つの項目を見ます:タスクタイプ、トークン長、リスクレベル、対外送信の有無。
分類、欄抽出、フォーマット変換は通常Haiku。要約、返信、文案、コードパッチはSonnet。長文コンテキスト、多文書推論、アーキテクチャ決定、複雑レビューはOpusまたは人手レビューに割り当てます。
最も簡単な方法はtask_type → default_modelの対応表を作り、トークン超過(例:8,000超)、高リスク、信頼度0.75未満で昇格条件を加えることです。
Q3 ルーティングミスが起きたらどうなりますか?フォールバックはどう設計しますか?
ルーティングミスは品質低下、処理失敗、対外誤出力の3つの結果を招きます。低リスクタスクはリトライで対応可能ですが、高リスクは昇格または人手レビューが必須です。
推奨フォールバックチェーンはHaiku → Sonnet → Opus / 人手レビューです。Haikuが形式エラー、信頼度不足、入力過長、金額・法務関連の場合は即Sonnetに昇格。Sonnetも不確定なら自動送信せず草稿のみ生成します。
Q4 多 LLMルーティングは自作が必要ですか?既存ツールはありますか?
必ずしもゼロから作る必要はありません。小規模チームはn8n、Make、Zapier、LangChain、LlamaIndex、または自社バックエンドでルールベースルーティングを構築可能です。重要なのはログ管理、フォールバック、品質サンプリングをしっかり行うことです。
タスクタイプが固定されているならif-elseでの自作が最速です。入力が動的ならLLM-as-Routerを追加検討してください。
Q5 いつ多 LLMルーティングを導入すべきでないですか?
月間APIコストがNT$1,000未満の場合は複雑なルーティングは不要です。この段階ではプロンプト整理、不要入力削減、キャッシュ活用を優先すべきです。
月額がNT$5,000を超え、同種タスクを毎日数百回実行する場合に多 LLMルーティングの効果が顕著に現れます。
関連記事
多 LLMルーティングのルールをAIチームのワークフローに組み込み、「全Sonnet」から「Haiku / Sonnet / Opusの階層化」へ移行しましょう。カスタマーサポート、コンテンツ、CRM、社内ナレッジベースの導入を検討される場合はAIcycleサービスまたはチームまでお問い合わせください。お客様の実際のトークンログをもとにBefore/Afterの試算を提供いたします。