多 LLM 路由實戰:怎麼省 60% AI API 成本(Sonnet 4.6 + Haiku 4.5 分流)
多 LLM 路由是把任務按複雜度分流到不同模型,透過 Haiku 4.5、Sonnet 4.6、Opus 4.7 的成本差,解決 AI API 月費失控。月 5M tokens 實測可省約 60%。
為什麼月底 AI 帳單越長越難看?
AI API 成本爆掉,通常不是因為模型變貴,而是因為你把所有事情都交給同一個大模型。
我們看過不少中小企業的 AI 導入路徑:第一個月只是寫文案、摘要會議紀錄、整理客服訊息,月費大概 NT$3,000。第二個月開始接進 CRM、客服信箱、社群排程、內部知識庫,token 成本就往 NT$10,000 跑。第三個月加上自動化 agent、批次改寫、名單清理,月費直接到 NT$30,000+。
問題不是 AI 不值得花錢,而是任務沒有分級。
一封客服信要不要用 Claude Sonnet 4.6?也許要。把 3,000 筆名單分成「B2B / B2C / 不確定」要不要用 Sonnet?大多數情況不用。把商品標題改成固定格式、抽出公司名稱、把 JSON 補齊欄位,這些都不是高階推理題。
大部分人做 AI 自動化會踩這個坑:先接 API,看到效果不錯,就把所有流程都丟給最強模型。短期很順,月底才發現每一個小任務都在用高級人工費率計價。
token 成本可以想成 AI 的「用量電費」。token 是模型讀入與輸出的文字單位,input token 是你丟進去的內容,output token 是模型回你的內容。任務越長、跑越多次、用越貴的模型,帳單就越高。
如果公司已經在做 Claude / Codex / Gemini 工具組合,下一步不該只是再加工具,而是把模型使用權限拆細:哪些任務只需要便宜模型,哪些任務才需要高階模型。
多 LLM 路由的核心價值就在這裡:不是少用 AI,而是把 AI 用在對的位置。
多 LLM 路由是什麼?一句話講完
多 LLM 路由就是「先判斷任務難度,再把任務送到對應模型」。
簡單任務送 Haiku 4.5,中等任務送 Sonnet 4.6,複雜任務才送 Opus 4.7。你可以把它想成公司裡的工作分派:資料整理交給助理,標準分析交給資深專員,重大決策才請顧問進來。
這不是為了追求技術漂亮,而是為了讓每一筆 token 成本有合理回報。
根據 Anthropic 官方 pricing 與模型文件,Claude 系列模型有不同價格、速度與能力定位,可參考 Anthropic pricing 與 Claude models docs。外部連結的 rel="noopener" 由前端模板統一處理。
成本公式很簡單:
節省 % = 1 - (Σ 各模型費用) / (全 Sonnet 費用)如果原本每月 5M tokens 全部走 Sonnet,成本約 NT$15,000。改成 70% Haiku、25% Sonnet、5% Opus 後,成本約 NT$5,400 到 NT$6,000。省下約 NT$9,000 到 NT$9,600,也就是 60% 左右。
這 60% 不是魔法,主要來自一件事:70% 以上任務其實不需要 Sonnet。
我們實測了名單分類、文案格式改寫、欄位抽取、FAQ 摘要、客服信件草稿等任務,結果很明顯:只要任務有固定格式、低風險、答案可驗證,Haiku 4.5 的表現通常夠用。真正需要 Sonnet 4.6 的,是需要判斷語氣、整合多段資訊、產出可直接對外使用內容的任務。
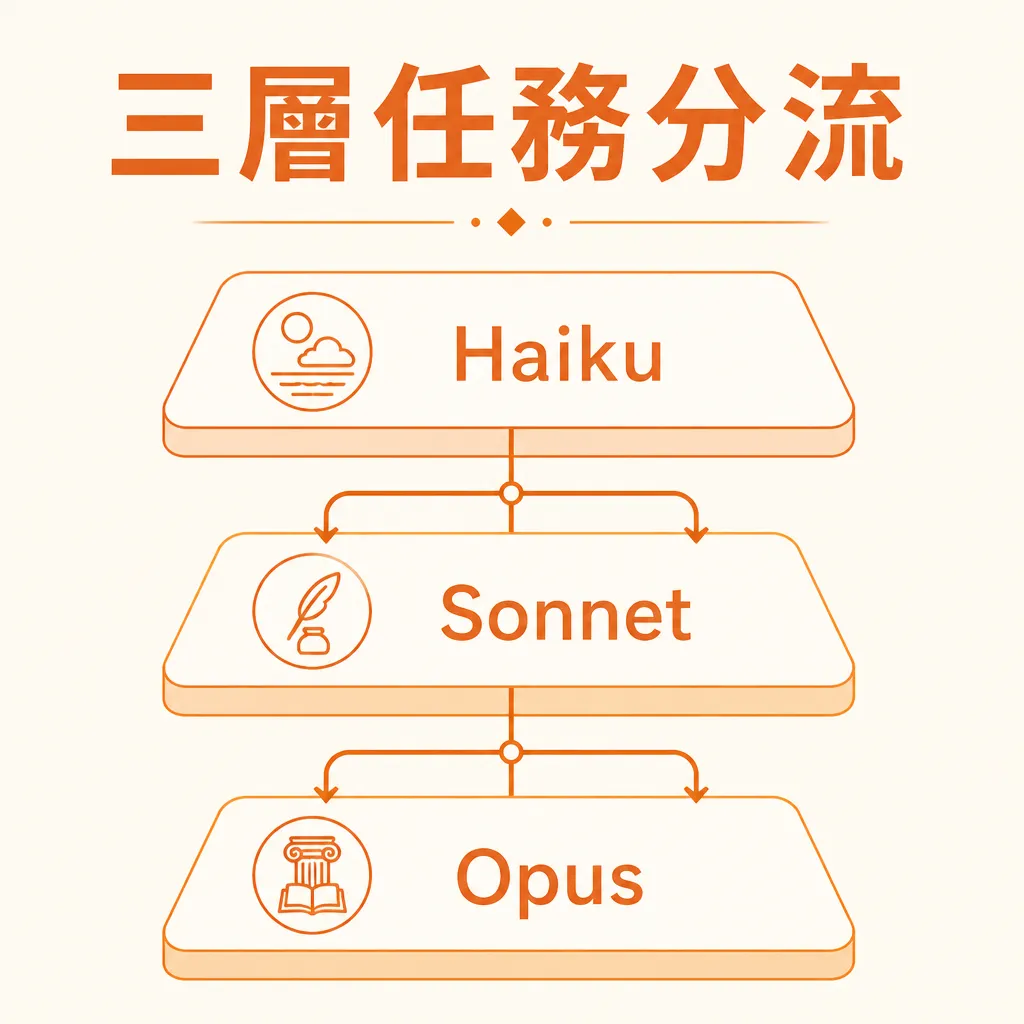
任務複雜度分三層:Haiku / Sonnet / Opus 怎麼挑
模型分流最怕憑感覺。正確做法是先把任務分成三層,再把每一層寫進 workflow。
這裡的關鍵不是「哪個模型最聰明」,而是「哪個模型剛好夠用」。對中小企業來說,剛好夠用比最強更重要,因為每月有幾萬次自動化呼叫時,單次差價會被放大。
| 分類 | 範例 | 模型 | 月 token 估算 | 月成本估算 |
|---|---|---|---|---|
| Tier 1(瑣碎) | 分類、抽欄位、改寫格式、簡單翻譯、標籤判斷 | Haiku 4.5 | 3.5M tokens | 約 NT$900-1,200 |
| Tier 2(標準) | 摘要、回信、代碼補丁、社群文案、銷售信草稿 | Sonnet 4.6 | 1.25M tokens | 約 NT$3,600-4,000 |
| Tier 3(戰略 / 長 context) | 架構決策、跨檔重構、複雜 review、策略判斷 | Opus 4.7 | 0.25M tokens | 約 NT$900-1,200 |
上表的 token 與費用是用月 5M tokens 的情境估算。實際帳單會受 input / output 比例、匯率、cache 命中率、模型官方定價變動影響,所以正式導入前要用自己的 logs 重算。
Tier 1(瑣碎任務)→ Haiku 4.5
Tier 1 的判斷標準很直接:答案格式固定、錯了容易抓、任務不需要深度推理。
例如:
- 把 inbound lead 分成「高意圖 / 中意圖 / 低意圖」
- 從信件抽出姓名、公司、職稱、需求
- 把 200 字貼文改成 120 字短版
- 把英文產品摘要翻成繁體中文
- 判斷客服問題屬於帳務、技術、物流或退費
這些任務很適合 Haiku 4.5,因為你要的是速度與成本,不是深度思考。只要 prompt 寫清楚分類規則、輸出 JSON schema、失敗時回傳 unknown,品質通常可以被監控。
我們實測過一批 1,000 筆表單線索,原本全丟 Sonnet 做分類,成本不高但很浪費。改用 Haiku 後,分類準確率維持在可接受區間,成本降到原本一小段。真正需要人工看的,是 unknown 與低信心分數樣本。
Tier 2(標準推理)→ Sonnet 4.6
Tier 2 是多數 AI workflow 的主力層。任務需要理解上下文、取捨資訊、控制語氣,但還不到戰略決策。
例如:
- 把 30 分鐘會議逐字稿整理成行動項目
- 回覆客戶抱怨信,保留品牌語氣
- 依據文章大綱產出 LinkedIn 貼文
- 幫工程師產出小型代碼補丁
- 把銷售通話紀錄轉成 CRM note
這一層建議用 Sonnet 4.6,因為它在品質、速度、成本之間比較平衡。尤其是對外內容、客服回信、業務信件,只要語氣失準就會造成品牌成本,不能只看 token 價格。
如果你正在規劃 低成本 AI 導入路徑,Tier 2 通常會是第一批正式上線的流程。它能帶來明顯人力節省,也比較容易算 ROI。
Tier 3(戰略 / code review 終審)→ Opus 4.7
Tier 3 是少量但高風險的任務。這些任務失敗一次的成本,可能比省下的 API 費用高很多。
例如:
- 判斷 AI 自動化架構要不要拆服務
- 跨檔重構前的風險分析
- code review 終審與安全檢查
- 內容策略、定位、轉換漏斗設計
- 長 context window(上下文長度)內的多文件推理
這層可以保留給 Opus 4.7,或你公司內部認定的最高階模型。用量不需要多,重點是把它放在最值得的位置。
一個健康的成本結構不是「完全不用大模型」,而是「大模型只做大模型該做的事」。
路由架構 3 種:規則、LLM-as-Router、混合
多 LLM 路由可以很簡單,也可以很複雜。中小企業不需要一開始就做完整模型治理平台,先從可觀測、可回滾、可解釋的架構開始。
A:規則路由(推薦中小企業起手)
規則路由就是用 if-else、任務類型、token 長度、風險等級來決定模型。
範例規則:
if task_type in ["分類", "欄位抽取", "格式改寫"]:
model = "Haiku 4.5"
elif token_count > 8000 or risk_level == "high":
model = "Sonnet 4.6"
elif task_type in ["架構決策", "複雜 review"]:
model = "Opus 4.7"
else:
model = "Sonnet 4.6"這種方法最穩、最便宜,也最容易 debug。你可以直接看 log:某任務為什麼被分到 Haiku,因為 task_type=分類;某任務為什麼升級到 Sonnet,因為輸入超過 8,000 tokens。
我們建議 80% 場景先用規則路由。尤其是內容生產、客服分流、CRM 資料清理、社群文案再利用,任務型態相對固定,不需要每次都讓另一個 LLM 來判斷。
B:LLM-as-Router(適合動態輸入)
LLM-as-Router 是先用一個便宜模型當分類器,判斷任務該走哪個模型。
例如,使用 Haiku 4.5 先讀使用者輸入,輸出:
{
"tier": "tier_2",
"model": "Sonnet 4.6",
"reason": "需要整合多段客訴內容並產出對外回覆",
"confidence": 0.86
}這種架構適合輸入很不規則的場景,例如客服信箱、開放式表單、內部 Slack 指令、agent 任務派工。它的彈性比較高,但也多了一次模型呼叫,所以不能無腦套到所有任務。
大部分人做 LLM-as-Router 會踩一個坑:router prompt 太抽象。不要問「這個任務難不難」,要給清楚 rubric,例如「是否需要多步推理」「是否對外發送」「是否涉及金額、法律、資安」「是否超過 6,000 tokens」。
C:混合架構(生產環境推薦)
生產環境最推薦混合架構:規則為主,LLM fallback。
做法是先用明確規則處理 70% 到 80% 任務;只有遇到規則判斷不出來、信心不足、輸入異常時,才呼叫 Haiku 4.5 當 router。若 router 仍不確定,就升級到 Sonnet 4.6。
一個實用流程如下:
| 階段 | 判斷方式 | 結果 |
|---|---|---|
| 第 1 層 | task_type、token_count、risk_level | 直接分到 Haiku / Sonnet / Opus |
| 第 2 層 | 規則無法判斷時,用 Haiku 當 router | 回傳 tier、confidence、reason |
| 第 3 層 | confidence < 0.75 或高風險 | 升級 Sonnet |
| 第 4 層 | Sonnet 標記不確定或高影響決策 | 升級 Opus 或人工審核 |
混合架構的好處是成本可控,又不會被僵硬規則卡死。它也比較容易寫進 ai-team workflow:每個任務先有預設模型,再有升級條件。
實際省多少?月 5M tokens 全表試算
我們用月 5M tokens 做一個中小企業常見情境。這家公司有客服摘要、名單分類、社群文案、內部 SOP 問答、簡單 code patch,每天跑數百到數千次 API 呼叫。
Before 是所有任務全走 Sonnet 4.6:
| 項目 | 模型 | token 占比 | 月 tokens | 月成本估算 |
|---|---|---|---|---|
| 全部任務 | Sonnet 4.6 | 100% | 5M | 約 NT$15,000 |
| 合計 | - | 100% | 5M | 約 NT$15,000 |
After 是規則路由 70 / 25 / 5 分流:
| 任務層級 | 模型 | token 占比 | 月 tokens | 月成本估算 |
|---|---|---|---|---|
| Tier 1 瑣碎任務 | Haiku 4.5 | 70% | 3.5M | 約 NT$900-1,200 |
| Tier 2 標準任務 | Sonnet 4.6 | 25% | 1.25M | 約 NT$3,600-4,000 |
| Tier 3 戰略任務 | Opus 4.7 | 5% | 0.25M | 約 NT$900-1,200 |
| 合計 | - | 100% | 5M | 約 NT$5,400-6,000 |
Before / After 對比:
| 指標 | Before:全 Sonnet | After:多 LLM 路由 |
|---|---|---|
| 月 tokens | 5M | 5M |
| 模型配置 | Sonnet 100% | Haiku 70% / Sonnet 25% / Opus 5% |
| 月成本 | 約 NT$15,000 | 約 NT$5,400-6,000 |
| 月省下 | - | 約 NT$9,000-9,600 |
| 成本降幅 | - | 約 60% |
再換成經營語言來看:
| 項目 | 數字 |
|---|---|
| 每月節省 | NT$9,000-9,600 |
| 每年節省 | NT$108,000-115,200 |
| 可換成 | 內容助理工時、廣告測試預算、CRM 清理專案 |
| 導入成本回收 | 若建置費 NT$30,000,約 3-4 個月回收 |
這也是為什麼 AI 成本要和 ROI 一起看。單看 API 費用會覺得只是省幾千元,但如果你正在拆 AI 團隊 ROI,每月固定省下的 API 成本會直接改善毛利。
還有一個重點:這裡沒有把 prompt cache 算進去。如果你的 workflow 常常重複丟同一份系統 prompt、品牌語氣規則、知識庫摘要,prompt cache 可能再降一段成本。

路由實作 3 個常見失誤
多 LLM 路由不是把 Haiku 塞到所有地方。真正難的不是分流,而是知道什麼時候不能省。
第一個失誤:過度路由 Haiku。
Haiku 4.5 很適合分類、抽欄位、格式整理,但複雜推理會出問題。省小錢敗大事,通常發生在這些場景:對外客服回覆、合約條款摘要、技術決策、跨文件分析、需要長 context window 的任務。
解法是把品質指標寫進規則。只要任務具備高風險、不可逆、對外發送、金額判斷、法律或資安內容,就不要直接走 Haiku。即使先走 Haiku,也要送 Sonnet 複核。
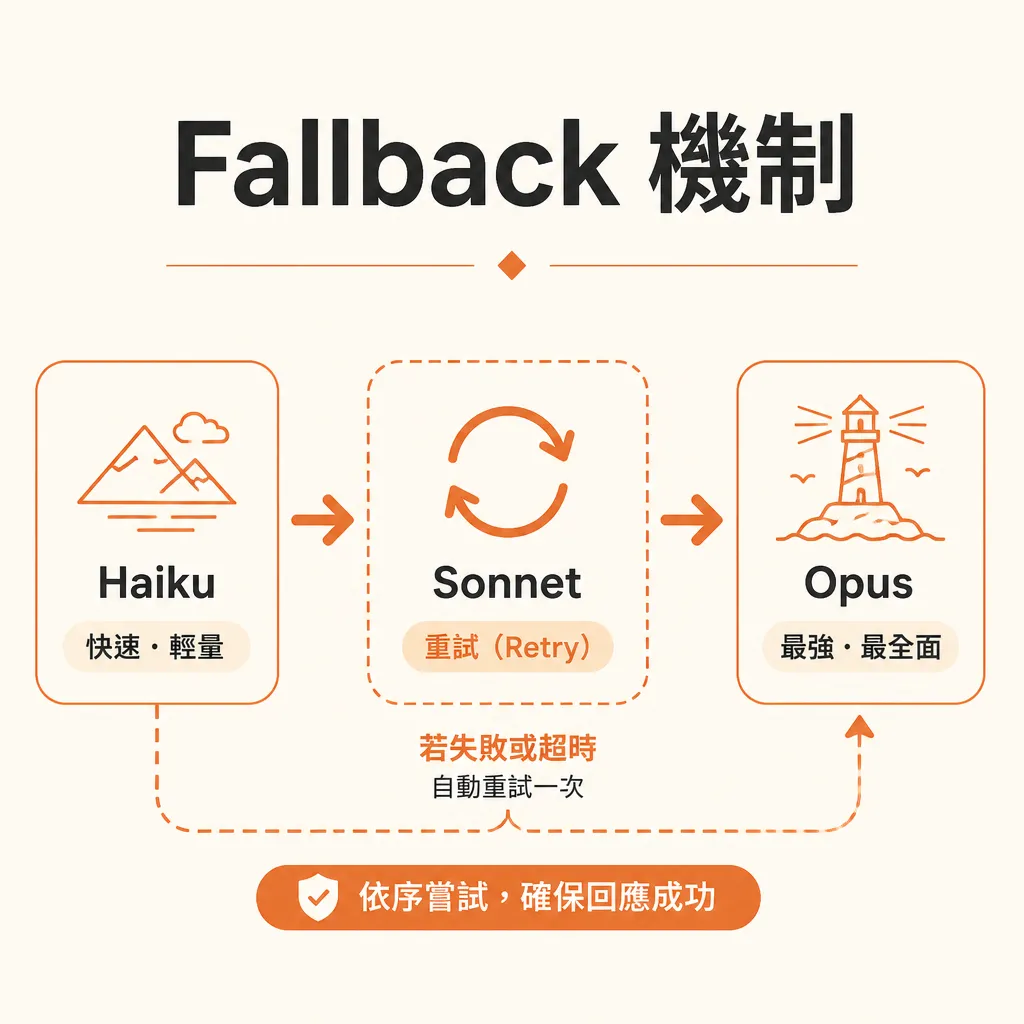
第二個失誤:沒做 fallback。
很多團隊只寫了「分類任務走 Haiku」,但沒寫「Haiku 失敗怎麼辦」。結果是 JSON 格式錯、信心分數低、輸入太長、答案空白時,流程直接掛掉。
基本 fallback 規則應該長這樣:
Haiku 回傳格式錯誤 → retry 1 次
retry 後仍失敗 → 升級 Sonnet
Sonnet 仍不確定 → 標記人工 review
高風險任務 → 不自動發送,只產生草稿第三個失誤:忽略 prompt cache。
有些團隊花很多時間做模型分流,卻每次都重送 5,000 tokens 的品牌規則、產品知識、客服 SOP。這時候 prompt cache 的節省可能比模型分流更大。
尤其是 5 分鐘 TTL(time to live,快取有效時間)內大量重複呼叫的情境,例如批次改寫 200 篇商品描述、同一份知識庫回答 500 個問題、同一套品牌規則產 100 則社群文案,cache 命中率會直接影響帳單。
建議把 cache、routing、fallback 一起設計,不要拆成三個孤島。
品質怎麼控?每月抽樣 review 公式
成本省下來只是第一步,品質沒有控住,最後會把省下的錢拿去補錯。
我們建議每月固定抽樣 50 個 Haiku 路由結果做人工 review。抽樣要覆蓋不同任務類型,例如分類 20 筆、欄位抽取 10 筆、格式改寫 10 筆、簡單翻譯 10 筆。
品質公式:
錯答率 = 錯誤樣本數 / 抽樣樣本數判斷規則:
| 錯答率 | 處理方式 |
|---|---|
| < 5% | 繼續路由到 Haiku |
| 5%-10% | 調整 prompt,增加 examples,觀察下月 |
| > 10% | 升級到 Sonnet,重新定義任務邊界 |
為什麼是 5%?因為大多數中小企業的 AI 自動化不是研究專案,而是營運流程。5% 錯答率代表每 100 次會有 5 次需要修正,這在低風險任務可以接受,但在對外訊息、報價、合約、醫療、法律、資安場景就不一定。
品質監控不要只看「對或錯」,還要看三個指標:
| 指標 | 定義 | 風險訊號 |
|---|---|---|
| 格式成功率 | 是否符合 JSON / Markdown / 欄位 schema | 低於 98% 要調 prompt |
| 升級率 | Haiku 被 fallback 到 Sonnet 的比例 | 突然升高代表任務輸入變了 |
| 人工修正時間 | 人員每筆修正花多久 | 若超過省下時間,路由不划算 |
把這些指標放進每月營運 review,比單看 API 帳單更有用。你會知道哪些任務真的適合便宜模型,哪些只是看起來便宜。
如果你已經在算 AI 導入 ROI,建議把「API 成本節省」「人工修正時間」「錯答造成的返工」放進同一張表。這樣才看得到淨效益。
常見問題(FAQ)— 至少 4 題(觸發 FAQPage schema)
Q1 Haiku 4.5 真的可以取代 Sonnet 嗎?
不能完全取代。Haiku 4.5 適合低風險、格式固定、答案可驗證的任務,例如分類、欄位抽取、短文改寫、簡單翻譯。
Sonnet 4.6 仍然適合標準推理、對外內容、客服回覆、代碼補丁等任務。正確做法不是用 Haiku 取代 Sonnet,而是讓 Haiku 吃掉 60% 到 70% 的瑣碎任務。
Q2 規則路由怎麼判斷該走哪個模型?
先看四個欄位:任務類型、token 長度、風險等級、是否對外發送。
分類、抽欄位、格式改寫通常走 Haiku。摘要、回信、文案、代碼補丁走 Sonnet。長 context、多文件推理、架構決策、複雜 review 走 Opus 或人工審核。
最簡單的起手式是建立 task_type → default_model 對照表,再加上升級條件,例如 token 超過 8,000、風險為 high、confidence 低於 0.75。
Q3 路由錯了會怎樣?怎麼設 fallback?
路由錯了可能有三種結果:品質下降、流程失敗、對外輸出錯誤。低風險任務可以靠 retry 解決,高風險任務一定要升級或人工審核。
建議 fallback 鏈是 Haiku → Sonnet → Opus / human review。當 Haiku 回傳格式錯、信心不足、輸入超長、內容涉及金額或法律時,直接升級到 Sonnet。若 Sonnet 仍標記不確定,就不要自動發送。
Q4 多 LLM 是不是要自己寫 router?有沒有現成工具?
不一定要從零開始。小團隊可以先在 n8n、Make、Zapier、LangChain、LlamaIndex 或自家後端寫規則路由。重點不是工具名稱,而是 logs、fallback、品質抽樣要做完整。
如果你的流程已經有固定任務類型,自己寫 if-else 反而最快。若輸入很動態,再加 LLM-as-Router。
Q5 什麼時候不該做多 LLM 路由?
如果你每月 API 成本不到 NT$1,000,先不要做複雜路由。這時候更該優先整理 prompt、減少不必要輸入、使用 cache。
當月費穩定超過 NT$5,000,或同一類任務每天跑數百次,多 LLM 路由才會明顯回收。
延伸閱讀
把多 LLM routing 規則寫進你的 ai-team workflow,從「全 Sonnet」改成「Haiku / Sonnet / Opus 分層」。如果你要導入到客服、內容、CRM 或內部知識庫流程,請看 AIcycle 服務 或聯絡團隊,我們會用你的實際 token logs 先算一版 Before / After。